Kuidas lugeda/kirjutada Juku ketaste sisu?¶
Juku 786/788 kB kettad on kahepoolsed topelttihedusega (DSDD) kettad, millel on kummalgi poolel 80 rada, millest igaüks koosneb 40 sektorist, millest igaüks mahutab 128 baiti. See teeb kokku 2x80 = 160 rada, 40 x 128 = 5120 baiti ja kokku ketta suuruseks 160x5120 = 819 200 baiti. Lugemise teeb keerukaks, et need baidid pole talletatud sisu mõttes mitte järjest, vaid "segamini paisatud". Seetõttu ei või seda võtta järjestikuse 819 kB andmekogumina ja selle osiste olemasolu ignoreerida, vaid tuleb segadus selle eri taseme põhjusest lähtuvalt likvideerida.
Töö teevad ära cpmtools ja libdsk käsikäes ning vajalikud konfifailid on:
- diskdefs (võib käia nt
/etc/cpmtoolsvõi/usr/local/sharealla) - libdskrc (võib käia nt
/usr/local/share/LibDskalla või kodukataloogi kujul.libdskrc)
Aga huvilistele veidi pikemalt köögipoolest...
| FDMAINT | DEC Rainbow 100 |
|---|---|
 |
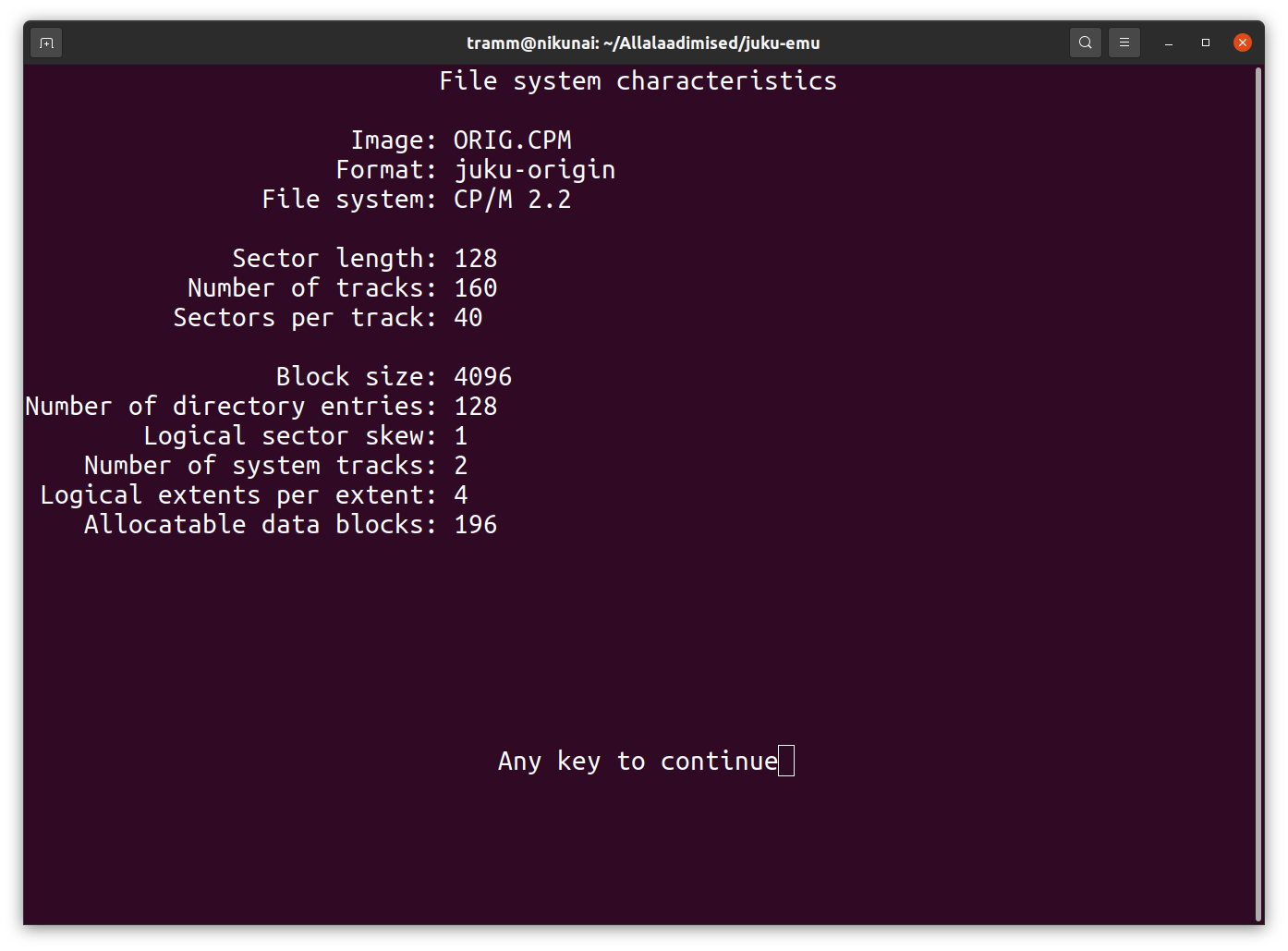
Ketta loogilise bloki suurus on 4096, igasse sellisesse blokki mahub 32 sektorit, loogilissi blokke mahub kogu ketta mahu sisse 819200/4096 = 200. Kui eeldada, et neist üks on kasutusel failide kataloogimise blokiks ja kaks reserveeritud süsteemi buutimiseks, siis jääb järgi 200-3 = 197. Seega on Juku ketta kasutatav maht 197x4096 = 806 912 baiti, mis on omakorda 806912/1024 = 788 kB.
Juku ketaste spetsiifiline topeltsegadus¶
Juku EKDOS 2.30 lähtekoodi päises on dokumenteeritud rasvases kirjas, et ketta formaadi aluseks on DEC Rainbow 100 flopiformaat. Lähtekood annab ka teada ülejäänud juba mainitud parameetrid:
; DPB constants for 5" 96 TPI DSDD diskettes (2x80 tracks):
TRACKS EQU 160 ; 5"DD
BLKSIZ EQU 4096 ; block length
DIRTRK EQU 2 ; directory track # (3 if 5"SD)
BLOCKS EQU 197 ; (TRACKS-DIRTRK)*CPMSPT/(BLKSIZ/128)-1
DIRENT EQU 128 ; directory entries
DIRCHK EQU 20H
Juba DEC Rainbow 100 on ajalooliselt tunnustatud peavalu, sest selle paisktabel ei ühildu teiste tootjate standarditega. Juku kasutab/viitab Rainbow kettaformaati ilmselt pigem juhuslikel põhjustel või kuna selle kettalugeja ühendas kaks ühepoolset kettalugejat ning sobis seega teatud määral koodidoonoriks -- igatahes Juku paisktabel tundub peale vaadates veel omal moel eksootiline ja on samuti leitav lähtekoodist:
; *** Sector translate vectors, two 40 byte areas ***
;
TRANS: DB 1,2,3,4,9,10,11,12
DB 17,18,19,20,25,26,27,28
DB 33,34,35,36,5,6,7,8
DB 13,14,15,16,21,22,23,24
DB 29,30,31,32,37,38,39,40
;
TRANS1: DB 1,2,3,4,9,10,11,12
DB 17,18,19,20,25,26,27,28
DB 33,34,35,36,5,6,7,8
DB 13,14,15,16,21,22,23,24
DB 29,30,31,32,37,38,39,40
Ilmselt lähtub see formaliseering andmete tegelikust paiknemisest flopikettal, sest on näha, et paisktabel ehk skew table on tegelikult neljastest blokkidest nagu 1,2,3,4 või 33,34,35,36 koosnev ja kogu tabeli lihtsustatud väljendus oleks 1,3,5,7,9,2,4,6,8,10. Mis on sisuliselt, et sektoreid loetakse üle ühe nii, et 5 paarituarvulise järjekorranumbriga ja siis sama ala kohta 5 paarisarvulise järjekorranumbriga sektorit. Sellist järjest lugemise vältimist oli omal ajal väidetavalt vaja, et arvutid kettalt tulevaid andmeid ikka töödelda jõuaks ja puhvrid ei hakkaks üle ajama:
"Standard CP/M systems are shipped with a skew factor of 6, where six physical sectors are skipped between each logical read operation. This skew factor allows enough time between sectors for most programs to load their buffers without missing the next sector. In particular computer systems that use fast processors, memory, and disk subsystems, the skew factor might be changed to improve overall response."
Ilmselgelt on tänapäeva mõistes tegu tarbetu abinõuga ning seetõttu ei tee me midagi halba, kui paisktabelit lihtsustame. Küll aga ei piisa, kui söödame lihtsustatud või lihtsustamata paisktabeli cmptoolsile, sest kuigi ketta algus loetakse enam-vähem, siis esimestest failidest edasi läheb kõik juba parajaks segapudruks.
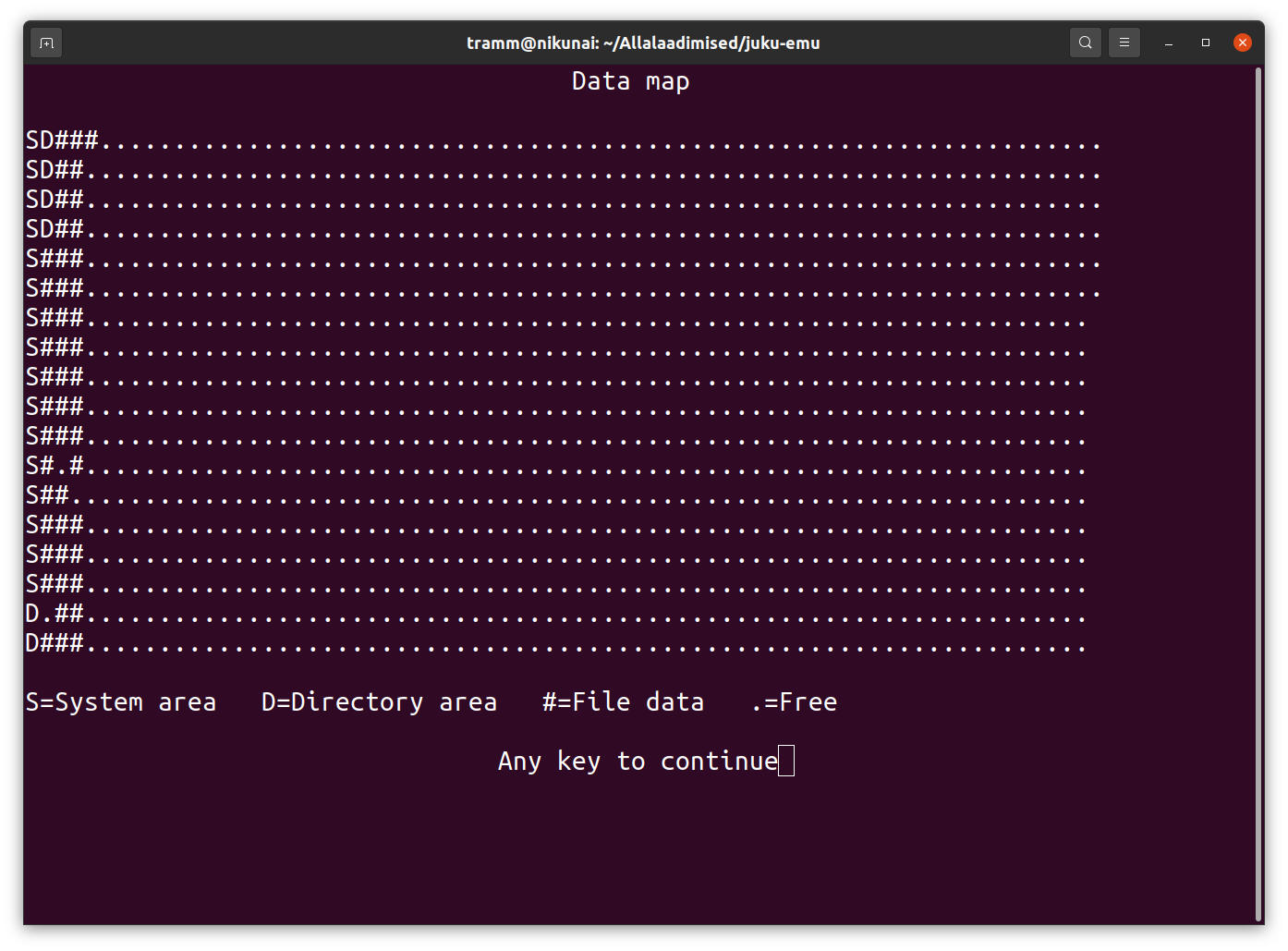
Kui seda putru aga lähemalt vaadelda, selgub et Juku kettaformaadil veel teine standardist hälbiv iseärasus, mis ei seostu üldse paisktabelitega. Nimelt kirjutatakse ketta ühe poole rajad täis ja siis minnakse teise poole radu kirjutama uuesi algusest, st ketta teisest servast. Tavapärane on kirjutada radu kordamööda ühele ja teisele poolele või hakata rajanumbritega ühte kettaserva jõudes nendega teiselt poolelt tagasi tulema. Seega on Juku ketastel tavapäraste ketaste suhtes segadus kahes mõttes, esiteks paisktabeli tõttu ja teiseks radade paigutuse tõttu kettal. Ette rutates võib ütelda, et paisktabel osutub radade segaduse lahendamise järel õigupoolest täiesti standardseks.
Millega ja mispidi neid siis lugeda?¶
Tegelikult cpmtools koos libdsk kettaseadetega loeb Juku diskid edukalt välja. Mõlemad on olemas kõigile viisakatele tänapäeva opsüsteemidele, aga peab veenduma, kas cpmtoolsi seadetes ehk ülal viidatud diskdef failis saab viidata libdski seadetes määratletud .libdskrc kirjetele. Sisuliselt on vaja teha kahte asja:
-
Tuleb
.libdiskrcfailis määratleda kettatõmmis kui kahe lugemispeaga loetav, st parameeterheads = 2ja silindrite arvuks määrata ühe poole radade arvcylinders = 80. Kettapooltele kirjutatavate radade järjekorra kohta peab ütlema, et neid kirjutatakse ketta väljast sissepoole liikudes samas suunas ja kui üks pool saab täis, siis jätkatakse teise poolega uuesti väljast sissepoole ehk parameetersides = outout. Kettatõmmise tüübi nimeks määrame "Juku" ehk paneme pealkirjaks[juku]. -
Tuleb cpmtoolsi
diskdefsfailis määratleda sobiv radade ja sektorite arv, määratleda eriotstarbelised rajad nagu süsteemile määratud kaks rada parameetrigaboottrk 2ja failide asukohti kettal kirjeldav rada parameetrigamaxdir 128. Ütlasi tulebdiskdefsfailis osutada, et kasutataks libdsk geomeetriat kettapoolte lugemiseks ning seda teeb parameeterlibdsk:format juku. Siin tuleb nüüd määratleda ka paisktabel ja seda on võimalik määratleda EKDOSi lähtekoodi viisil või lihtsustada nii, nagu ülal osutasin.
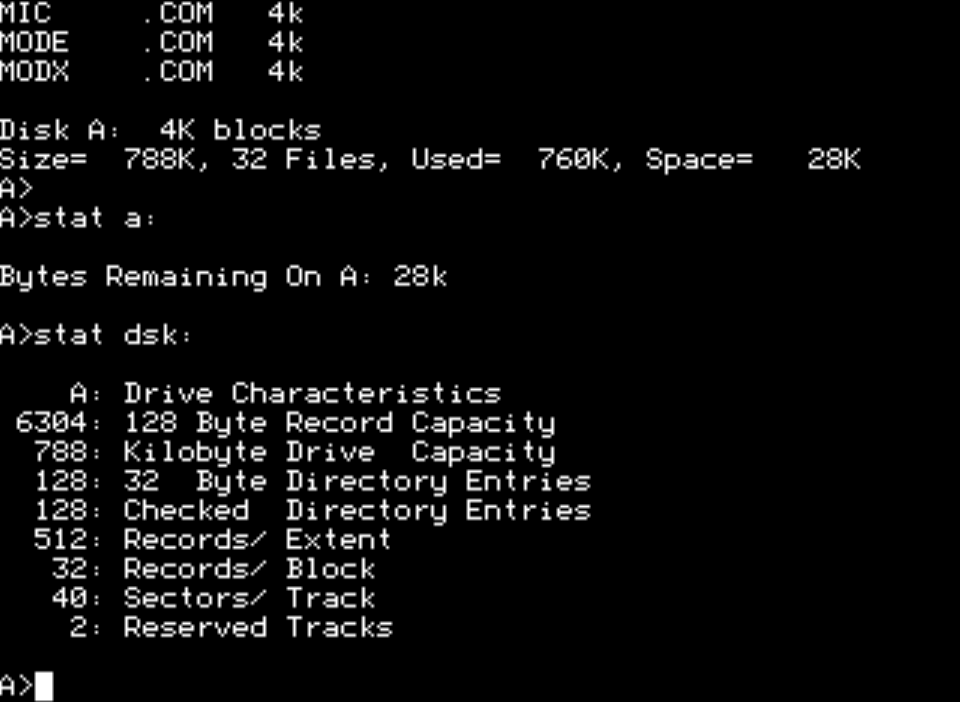
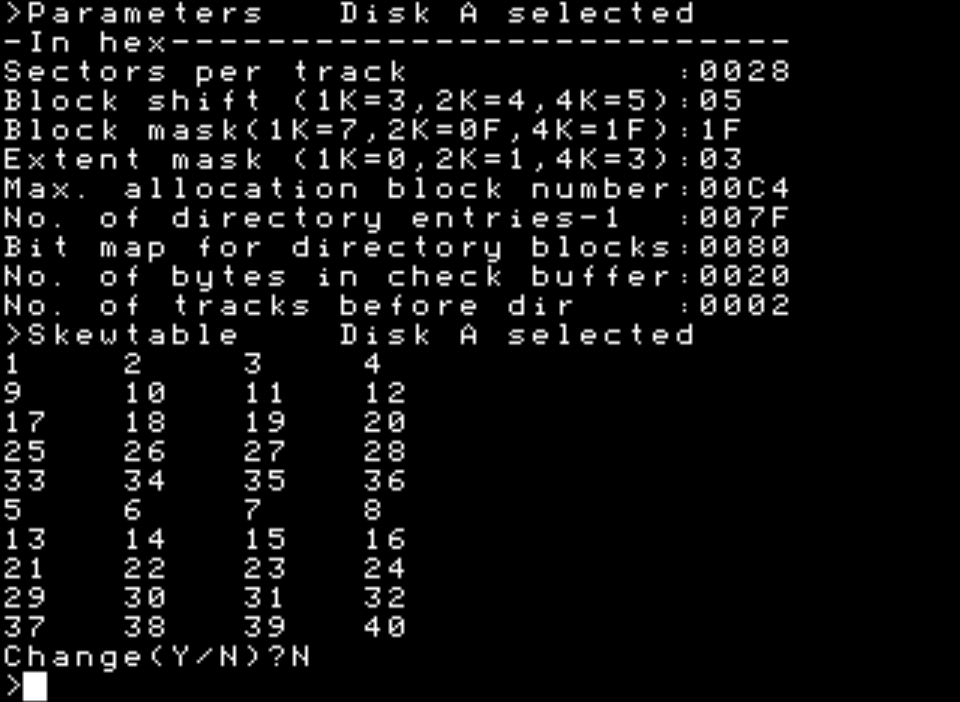
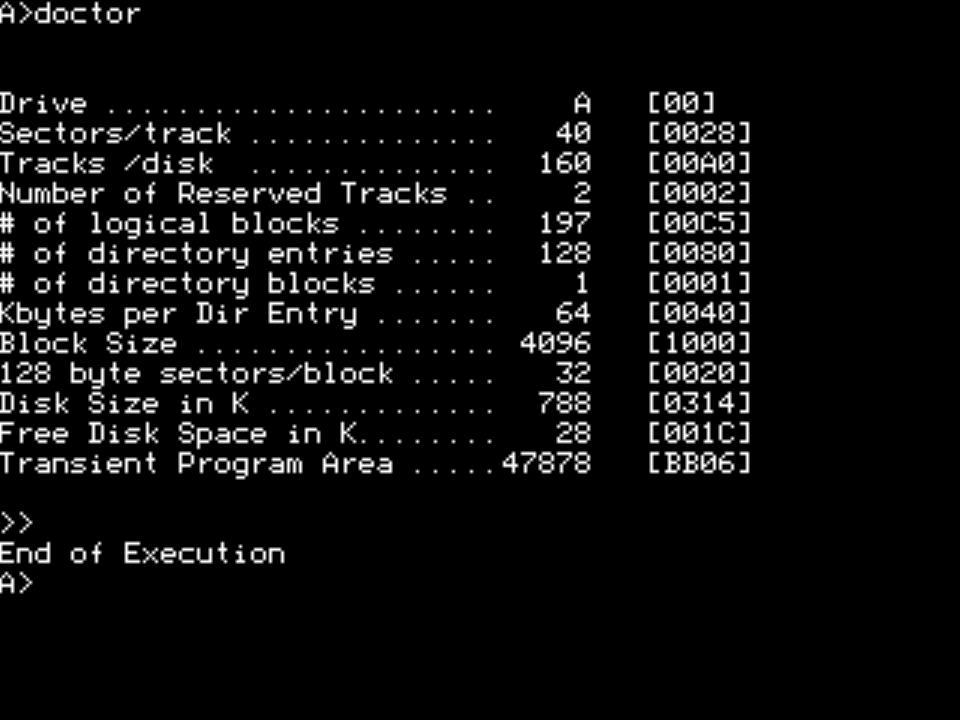
Kui alustuseks vaadata Juku enda utiliite, siis need näitavad ketta eri parameetreid samuti üpris erinevalt:
| STAT | KULT | DOCTOR |
|---|---|---|
 |
 |
 |
Juku algupärasele füüsilisele laotusele truuks jäädes peaksime määrama .libdiskrc failis parameetrid ilmselt nii:
[juku-origin]
description = Juku E5101 5.25" DSDD (2 x 80 x 40 * 128)
sides = outout
cylinders = 80
heads = 2
secsize = 128
sectors = 40
datarate = DD
Samamoodi austades algset paisktabelit peaks olema diskdefs kirje (küll tuleb tabeli väärtused muuta nullist algavaks):
# Juku E5101 original (DEC Rainbow 100 feat DSDD)
diskdef juku-origin
seclen 128
tracks 160
sectrk 40
blocksize 4096
skewtab 0,1,2,3,8,9,10,11,16,17,18,19,24,25,26,27,32,33,34,35,4,5,6,7,12,13,14,15,20,21,22,23,28,29,30,31,36,37,38,39
boottrk 2
maxdir 128
os 2.2
libdsk:format juku-origin
end
Kui lihtsustame aga paisktabeli ja ignoreerime ajaloolisi füüsilisi blokke, siis peaks sobima vastavalt:
[juku]
description = Juku E5101 5.25" DSDD (2 x 80 x 10 * 512)
sides = outout
cylinders = 80
heads = 2
secsize = 512
sectors = 10
datarate = DD
Ja cpmtoolsi diskdefs lühendatud paisktabeliga on lõpuks ketta poolte lugemise segaduse eemaldamise järel täiesti tavaline paiskfaktor väärtusega 2 ehk skew 2:
# Juku E5101 \w optimized skew (DEC Rainbow 100 feat DSDD)
diskdef juku
seclen 512
tracks 160
sectrk 10
blocksize 4096
skew 2
#skewtab 0,2,4,6,8,1,3,5,7,9
boottrk 2
maxdir 128
os 2.2
libdsk:format juku
end
Teoreetiliselt võiks libdsk formaati ka ignoreerida, aga siis tuleks kirjeldada kõik sektorid ja nende blokid ühel rajal ning paisktabelis ära tuua need kõigi sektorite kohta, mis teeks tabeli umbes 160x10x4 ≈ 6 kB pikkuseks -- mis ei ole küll tänapeäva mõistes päris maailmalõpp, aga cpmtools ei pruugi vaikimisi nii pikka tabelit seedida. Teine võimalus on, et doonoriks sobib mõni acorn libdsk formaat, mis on üks väheseid, milles outout lugemisviis kasutusel olla olnud (vt "used by some Acorn formats [and Juku]").
Lõppseis ja töö viljad¶
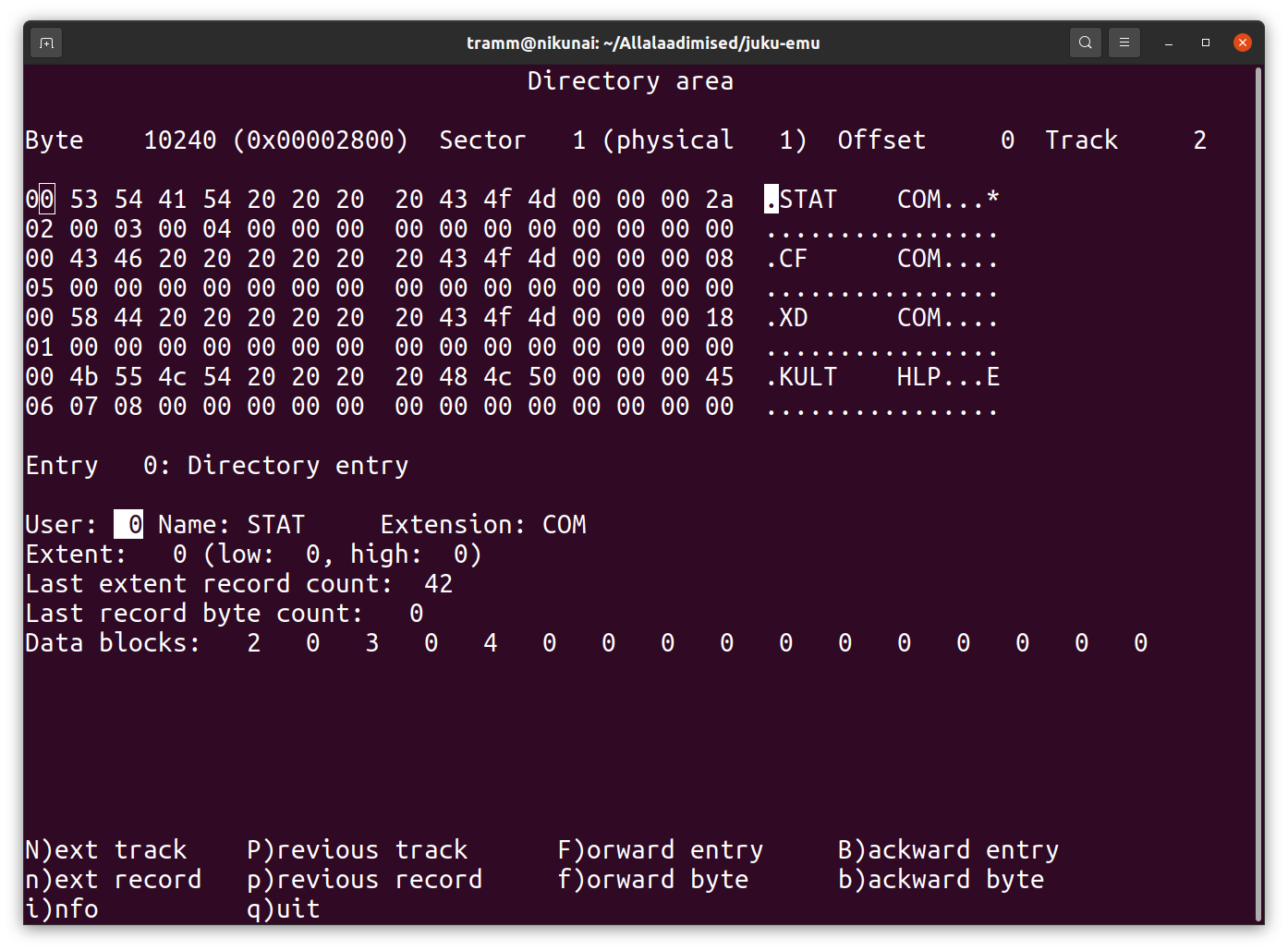
Lõpptulemus näeb cpmtoolsi fsed.cpm -f juku-origin ORIG.CPM ekraanil välja nii:
| Info (I) | Datamap (M) | Kataloogikirje (0x5000) |
|---|---|---|
 |
 |
 |
Ühtlasi peaks töötama kõik cpmtoolsi käsud, millega brausida ketaste sisu ning teha failioperatsioone kopeerimisest kustutamiseni:
cpmls -f juku DISK.CPM
cpmls -f juku -licF DISK.CPM
cpmcp -f juku GAMES.CPM 0:*.* jukugames
cpmcp -f juku GAMESX.CPM jukugames/INDY.* 0:
Kui määrata juku keskkonnamuutujas CPMTOOLSFMT vaikimisi formaadiks, siis võib -f juku ka ära jätta:
CPMTOOLSFMT="juku"
export CPMTOOLSFMT
Toetatud kettatüüpide ja -vormingute nimekirju libdsk poolel näitavad dskutil -types ja dskutil -formats, cpmtools lubatud formaatide nimekirja ei paista väljastavat ja nendega tuleb tutvuda diskdefs seadistusfaili tasemel. Õigupoolest on Juku ketaste lugemiseks täiendavate libdsk vahenditeta vaja cmptoolsi lähtekoodi täiendada vaid ühe reaga kahes funktsioons, mis juhendaks neid otsima radu kettatõmmisel õigest kohast ja sellise täiendusega CpmtoolsGUI JUKU versiooni leiab siit.
Ühesõnaga, on küll mõnevõrra tüütu kaevuda ajalooliste kettaformaatide iseärasustesse, kuid mõningase pusimise ja loomkatsete tulemusel saab ka maailma kõige unikaalsema CP/M kettaformaadi loetud. Juku tunnustuseks võib ütelda, et tõenäoliselt pole kunagi eksisteerinud ühtegi teist arvutisüsteemi, mis oleks ilma pusserdamiseta Juku kettaid suutnud lugeda -- seega kaksteist punkti ja ugrikrüpto eriauhind teadurile, kes selle välja mõtles!
P. S. Füüsilistest ketastest tõmmiste tegemine on ka huvitav, aga eraldi kirjatükki vääriv teema.